1. 概述
Apache Hudi 是一个快速迭代的数据湖存储系统,可以帮助企业构建和管理PB级数据湖,Hudi通过引入upserts、deletes和增量查询等原语将流式能力带入了批处理。这些特性使得统一服务层可提供更快、更新鲜的数据。Hudi表可存储在Hadoop兼容的分布式文件系统或者云上对象存储中,并且很好的集成了 Presto, Apache Hive, Apache Spark 和Apache Impala。Hudi开创了一种新的模型(数据组织形式),该模型将文件写入到一个更受管理的存储层,该存储层可以与主流查询引擎进行互操作,同时在项目演变方面有了一些有趣的经验。
本博客讨论Presto和Hudi集成的演变,同时讨论Presto-Hudi查询即将到来的文件Listing和查询计划优化。
2. Apache Hudi
Apache Hudi(简称Hudi)提供在DFS上存储超大规模数据集,同时使得流式处理如果批处理一样,该实现主要是通过如下两个原语实现。
Update/Delete记录: Hudi支持更新/删除记录,使用文件/记录级别索引,同时对写操作提供事务保证。查询可获取最新提交的快照来产生结果。
Change Streams: Hudi也支持增量获取表中所有更新/插入/删除的记录,从指定时间点开始进行增量查询。
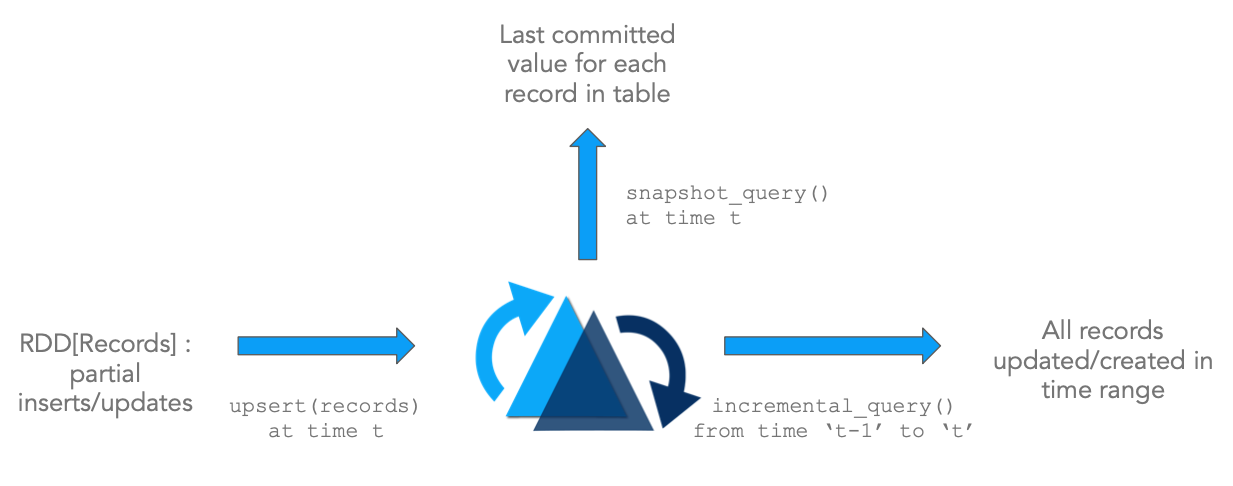
上图说明了Hudi的原语,配合这些原语可以直接在DFS抽象之上解锁流/增量处理功能。这和直接从Kafka Topic消费事件,然后使用状态存储来增量计算临时结果类似,该架构有很多优点。
提升效率: 摄取数据经常需要处理更新(例如CDC),删除(法律隐私条例)以及强制主键约束来确保数据质量。然而由于缺乏标准工具,数据工程师往往需要使用批处理作业来重新处理整天的事件或者每次运行时重新加载上游所有数据,这会导致浪费大量的资源。由于Hudi支持记录级别更新,只需要重新处理表中更新/删除的记录,大大提升了处理效率,而无需重写表的所有分区或事件。
更快的ETL/派生管道: 还有一种普遍情况,即一旦从外部源摄取数据,就使用Apache Spark/Apache Hive或任何其他数据处理框架构建派生的数据管道,以便为各种用例(如数据仓库、机器学习功能提取,甚至仅仅是分析)构建派生数据管道。通常该过程再次依赖于以代码或SQL表示的批处理作业,批量处理所有输入数据并重新计算所有输出结果。通过使用增量查询(而不是常规快照查询)查询一个或多个输入表,从而只处理来自上游表的增量更改,然后对目标派生表执行upsert或delete操作,可以显著加快这种数据管道的速度,如第一个图所示。
更新鲜的数据访问: 通常我们会添加更多的资源(例如内存)来提高性能指标(例如查询延迟)。Hudi从根本上改变了数据集的传统管理方式,这可能是大数据时代出现以来的第一次。增量地进行批处理可以使得管道运行时间少得多。相比以前的数据湖,现在数据可更快地被查询。
统一存储: 基于以上三个优点,在现有数据湖上进行更快、更轻的处理意味着不需要仅为了获得接近实时数据的访问而使用专门存储或数据集市。
2.1 Hudi表和查询类型
2.1.1 表类型
Hudi支持如下两种类型表
Copy On Write (COW): 使用列式存储格式(如parquet)存储数据,在写入时同步更新版本/重写数据。
Merge On Read (MOR): 使用列式存储格式(如parquet)+ 行存(如Avro)存储数据。更新被增量写入delta文件,后续会进行同步/异步压缩产生新的列式文件版本。
下表总结了两种表类型的trade-off。
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | 更高 | 更低 |
| 更新开销 (I/O) | 高(重写整个parquet文件) | 更低 (写入增量日志文件) |
| Parquet文件大小 | 更小(高update (I/0) 开销) | 更大 (低updaet开销) |
| 写放大 | 更低 (决定与Compaction策略) |
2.1.2 查询类型
Hudi支持如下查询类型
快照查询: 查询给定commit/compaction的表的最新快照。对于Merge-On-Read表,通过合并基础文件和增量文件来提供近实时数据(分钟级);对于Copy-On-Write表,对现有Parquet表提供了一个可插拔替换,同时提供了upsert/delete和其他特性。
增量查询: 查询给定commit/compaction之后新写入的数据,可为增量管道提供变更流。
读优化查询: 查询给定commit/compaction的表的最新快照。只提供最新版本的基础/列式数据文件,并可保证与非Hudi表相同的列式查询性能。
下表总结了不同查询类型之间的trade-off。
| Trade-off | 快照 | 读优化 |
|---|---|---|
| 数据延迟 | 更低 | 更高 |
| 查询延迟 | COW: 与parquet表相同。MOR: 更高 (合并基础/列式文件和行存增量文件) | 与COW快照查询有相同列式查询性能 |
下面动画简单演示了插入/更新如何存储在COW和MOR表中的步骤,以及沿着时间轴的查询结果。其中X轴表示每个查询类型的时间轴和查询结果。
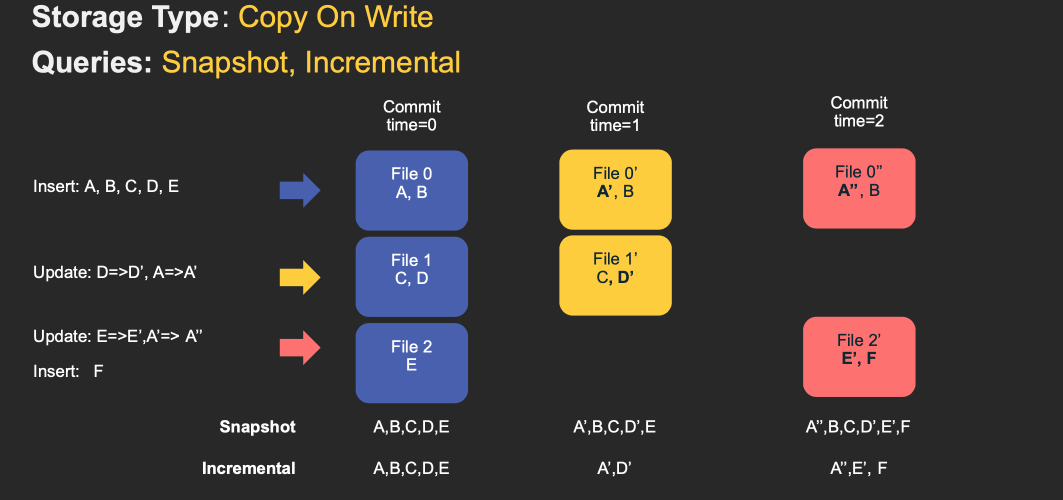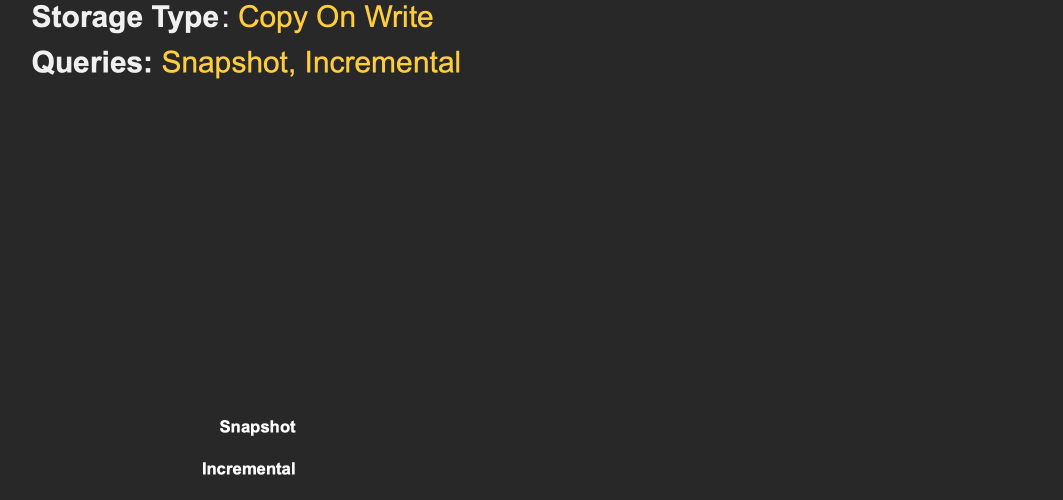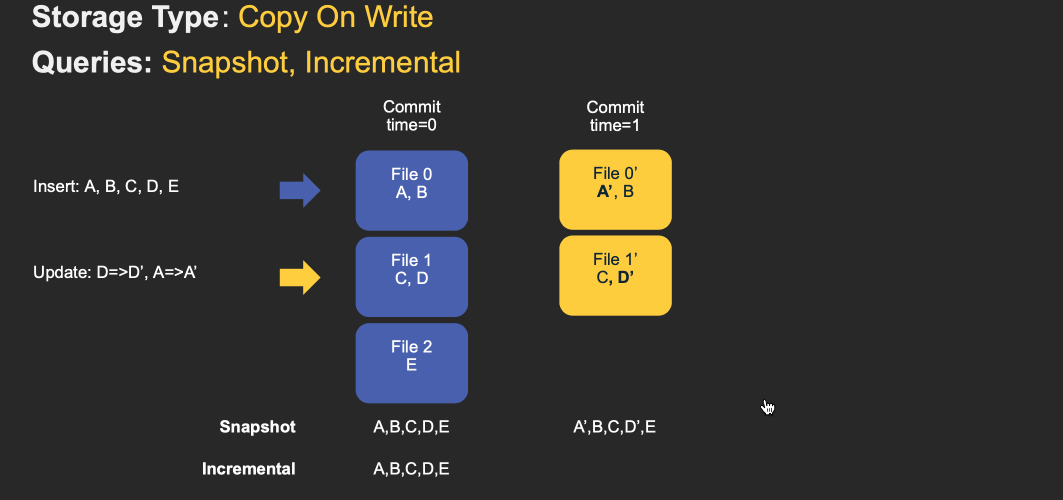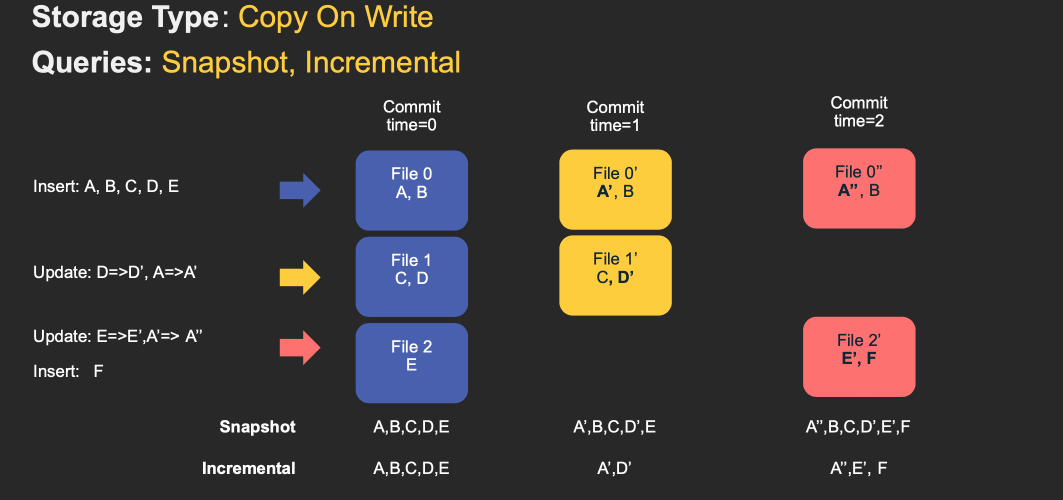
注意,作为写操作的一部分,表的commit被完全合并到表中。对于更新,包含该记录的文件将使用所有已更改记录的新值重新写入。对于插入,优先会将记录写入到每个分区路径中最小文件,直到它达到配置的最大大小。其他剩余的记录都将写入新的文件id组中,会保证再次满足大小要求。

MOR和COW在摄取数据方面经历了相同步骤。更新将写入属于最新文件版本的最新日志(delta)文件,而不进行合并。对于插入,Hudi支持2种模式:
写入log文件 - 当Hudi表可索引日志文件(例如HBase索引和即将到来的记录级别索引)。
写入parquet文件 - 当Hudi表不能索引日志文件(例如布隆索引)。
增量日志文件后面通过时间轴中的压缩(compaction)操作与基础parquet文件合并。这种表类型是最通用、高度高级的,为写入提供很大灵活性(指定不同的压缩策略、处理突发性写入流量等)和查询提供灵活性(例如权衡数据新鲜度和查询性能)。
3. Presto
3.1 早期Presto集成方案
Hudi设计于2016年中后期。那时我们就着手与Hadoop生态系统中的查询引擎集成。为了在Presto中实现这一点,正如社区建议的那样,我们引入了一个自定义注解@UseFileSplitsFromInputFormat。任何注册的Hive表(如果有此注解)都将通过调用相应的inputformat的getSplits()方法(而不是Presto Hive原生切片加载逻辑)来获取切片。通过Presto查询的Hudi表,只需简单调用HoodieParquetInputFormat.getSplits(). 集成非常简单只,需将相应的Hudi jar包放到<presto_install>/plugin/hive-hadoop2/目录下。它支持查询COW Hudi表,并读取MOR Hudi表的优化查询(只从压缩的基本parquet文件中获取数据)。在Uber,这种简单的集成已经支持每天超过100000次的Presto查询,这些查询来自使用Hudi管理的HDFS中的100PB的数据(原始数据和模型表)。
3.2 移除InputFormat.getSplits()
调用inputformat.getSplits()是个简单的集成,但是可能会导致对NameNode的大量RPC调用,以前的集成方法有几个缺点。
从Hudi返回的InputSplits不够。Presto需要知道每个InputSplit返回的文件状态和块位置。因此,对于每次切片乘以加载的分区数,这将增加2个额外的NameNode RPC调用。有时,NameNode承受很大的压力,会观察到背压。
此外对于Presto Split计算中加载的每个分区(每个loadPartition()调用),HoodieParquetInputFormat.getSplits()将被调用。这导致了冗余的Hudi表元数据Listing,其实可以被属于从查询扫描的表的所有分区复用。
我们开始重新思考Presto-Hudi的整合方案。在Uber,我们通过在Hudi上添加一个编译时依赖项来改变这个实现,并在BackgroundHiveSplitLoader构造函数中实例化HoodieTableMetadata一次。然后我们利用Hudi Api过滤分区文件,而不是调用HoodieParquetInputFormat.getSplits(),这大大减少了该路径中NameNode调用次数。
为了推广这种方法并使其可用于Presto-Hudi社区,我们在Presto的DirectoryLister接口中添加了一个新的API,它将接受PathFilter对象。对于Hudi表,我们提供了这个PathFilter对象HoodieROTablePathFilter,它将负责过滤为查询Hudi表而预先列出的文件,并获得与Uber内部解决方案相同的结果。
这一变化是从0.233版本的Presto开始提供,依赖Hudi版本为0.5.1-incubating。由于Hudi现在是一个编译时依赖项,因此不再需要在plugin目录中提供Hudi jar文件。
3.3 Presto支持查询Hudi MOR表
我们看到社区有越来越多人对使用Presto支持Hudi MOR表的快照查询感兴趣。之前Presto只支持查询Hudi表读优化查询(纯列式数据)。随着该PR https://github.com/prestodb/presto/pull/14795被合入,现在Presto(0.240及后面版本)已经支持查询MOR表的快照查询,这将通过在读取时合并基本文件(parquet数据)和日志文件(avro数据)使更新鲜的数据可用于查询。
在Hive中,这可以通过引入一个单独的InputFormat类来实现,该类提供了处理切片的方法,并引入了一个新的RecordReader类,该类可以扫描切片以获取记录。对于使用Hive查询MOR Hudi表,在Hudi中已经有类似类可用:
InputFormat - org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
InputSplit - org.apache.hudi.hadoop.realtime.HoodieRealtimeFileSplit
RecordReader - org.apache.hudi.hadoop.realtime.HoodieRealtimeRecordReader 在Presto中支持这一点需要理解Presto如何从Hive表中获取记录,并在该层中进行必要的修改。因为Presto使用其原生的ParquetPageSource而不是InputFormat的记录读取器,Presto将只显示基本Parquet文件,而不显示来自Hudi日志文件的实时更新,后者是avro数据(本质上与普通的读优化Hudi查询相同)。
为了让Hudi实时查询正常工作,我们确定并进行了以下必要更改:
向可序列化HiveSplit添加额外的元数据字段以存储Hudi切片信息。Presto-Hive将其拆分转换为可序列化的HiveSplit以进行传递。因为它需要标准的切片,所以它将丢失从FileSplit扩展的复杂切片中包含的任何额外信息的上下文。我们的第一个想法是简单地添加整个切片作为HiveSplit的一个额外的字段。但这并不起作用,因为复杂的切片不可序列化,而且还会复制基本切片数据。
相反我们添加了一个CustomSplitConverter接口。它接受一个自定义切片并返回一个易于序列化的String->String Map,其中包含来自自定义切片的额外数据。为了实现这点,我们还将此Map作为一个附加字段添加到Presto的HiveSplit中。我们创建了HudiRealtimeSplitConverter来实现用于Hudi实时查询的CustomSplitConverter接口。
从HiveSplit的额外元数据重新创建Hudi切片。现在我们已经掌握了HiveSplit中包含的自定义切片的完整信息,我们需要在读取切片之前识别并重新创建HoodieRealtimeFileSplit。CustomSplitConverter接口还有另一个方法,它接受普通的FileSplit和额外的split信息映射,并返回实际复杂的FileSplit,在本例中是HudiRealtimeFileSplit。
使用HoodieParquetRealtimeInputFormat中的HoodieRealtimeRecordReader读取重新创建的HoodieRealtimeFileSplit。Presto需要使用新的记录读取器来正确处理HudiRealtimeFileSplit中的额外信息。为此,我们引入了与第一个注释类似的另一个注解@UseRecordReaderFromInputFormat。这指示Presto使用Hive记录光标(使用InputFormat的记录读取器)而不是PageSource。Hive记录光标可以理解重新创建的自定义切片,并基于自定义切片设置其他信息/配置。
有了这些变更,Presto用户便可查询Hudi MOR表中更新鲜的数据了。
4. 下一步计划
下面是一些很有意思的工作(RFCs),可能也需要在Presto中支持。
RFC-12: Bootstrapping Hudi tables efficiently
ApacheHudi维护每个记录的元数据,使我们能够提供记录级别的更新、唯一的键语义和类似数据库的更改流。然而这意味着,要利用Hudi的upsert和增量处理能力,用户需要重写整个数据集,使其成为Hudi表。这个RFC提供了一种机制来高效地迁移他们的数据集,而不需要重写整个数据集,同时还提供了Hudi的全部功能。
这将通过在新的引导Hudi表中引用外部数据文件(来自源表)的机制来实现。由于数据可能驻留在外部位置(引导数据)或Hudi表的basepath(最近的数据)下,FileSplits将需要在这些位置上存储更多的元数据。这项工作还将利用并建立在我们当前添加的Presto MOR查询支持之上。
支持Hudi表增量和时间点时间旅行查询
增量查询允许我们从源Hudi表中提取变更日志。时间点查询允许在时间T1和T2之间获取Hudi表的状态。这些已经在Hive和Spark中得到支持。我们也在考虑在Presto中支持这个特性。
在Hive中,通过在JobConf中设置一些配置来支持增量查询,例如-query mode设置为INCREMENTAL、启动提交时间和要使用的最大提交数。在Spark中有一个特定的实现来支持增量查询—IncrementalRelation。为了在Presto中支持这一点,我们需要一种识别增量查询的方法。如果Presto不向hadoop Configuration对象传递会话配置,那么最初的想法是在metastore中将同一个表注册为增量表。然后使用查询谓词获取其他详细信息,如开始提交时间、最大提交时间等。
RFC-15: 查询计划和Listing优化
Hudi write client和Hudi查询需要对文件系统执行listStatus操作以获得文件系统的当前视图。在Uber,HDFS基础设施为Listing做了大量优化,但对于包含数千个分区的大型数据集以及每个分区在云/对象存储上有数千个文件的大型数据集来说,这可能是一个昂贵的操作。上面的RFC工作旨在消除Listing操作,提供更好的查询性能和更快的查找,只需将Hudi的时间轴元数据逐渐压缩到表状态的快照中。
该方案旨在解决:
存储和维护最新文件的元数据
维护表中所有列的统计信息,以帮助在扫描之前有效地修剪文件,这可以在引擎的查询规划阶段使用。
为此,Presto也需要一些变更。我们正在积极探索在查询规划阶段利用这些元数据的方法。这将是对Presto-Hudi集成的重要补充,并将进一步降低查询延迟。
记录级别索引
Upsert是Hudi表上一种流行的写操作,它依赖于索引将传入记录标记为Upsert。HoodieIndex在分区或非分区数据集中提供记录id到文件id的映射,实现有BloomFilters/Key ranges(用于临时数据)和Apache HBase(用于随机更新)支持。许多用户发现Apache HBase(或任何类似的key-value-store-backed索引)很昂贵,并且增加了运维开销。该工作试图提出一种新的索引格式,用于记录级别的索引,这是在Hudi中实现的。Hudi将存储和维护记录级索引(有HFile、RocksDB等可插拔存储实现支持)。这将被writer(摄取)和reader(摄取/查询)使用,并将显著提高upsert性能,而不是基于join的方法,或者是用于支持随机更新工作负载的布隆索引。这是查询引擎在列出文件之前修剪文件时可以利用这些信息的另一个领域。我们也在考虑一种在查询时利用Presto中的元数据的方法。
5. 总结
像Presto这样的查询引擎是用户了解Hudi优势的入口。随着不断增长的社区和活跃的开发路线图,Hudi中有许多有趣的工作,由于Hudi在上面的工作上投入了大量精力,因此只需要与Presto这样的系统进行深度集成。为此,我们期待着与Presto社区合作。我们欢迎您的建议反馈,并鼓励您作出贡献 ,与我们联系。
相关推荐



0评论