在说redis中的哈希(准确来说是一致性哈希)问题之前,先来看一个问题:为什么在分布式集群中一致性哈希会得到大量应用?
在一个分布式系统中,要将数据存储到具体某个节点,或者将来自客户端的请求分配到某个服务器节点做负载均衡,如果采用普通的hash取模算法进行映射,即如key.hashCode()%N,key代表数据的key,N是服务器节点数,使用上能达到预期效果。
但是如果此时要下线一个服务器或者上线一个新的服务器,那么原来的映射将全部失效。如果是做分布式存储,则需要做数据迁移;如果是做分布式缓存,则原来的缓存失效,需要让新增或下线的节点生效就需要做rehash,数据较大会比较消耗时间(其实这点对HashMap了解的,很熟悉这一点,HashMap在动态扩容进行rehash,数据量过大时很消耗时间影响性能)。这时,一致性哈希就派上用场了。
下面通过几个问题逐步介绍redis2.X和redis3.X中的一些特性,来了解一致性哈希在redis中的应用,以及遇到的问题,不同版本是如何解决的。
1. 假如有两台redis服务器,jedis客户端要存入数据到这两台服务器,它如何知道要存入哪台服务器?
这个就是开篇所说一般的做法:哈希取模。
key.hashcode() % nums(key是redis中的key,nums是redis服务器数)最终结果范围:0到nums-1
2. 此时新增一台redis服务器,数据能写入到新增的机器上吗?不能。还是对原有redis服务器数进行取模。
那么如何解决这一问题呢?nums不定义为redis服务器具体数,而是一个比较大的值:2^32,从而映射到一个比较大的空间内,拿key.hashcode*()% 2^32-1来确定存入的服务器。最终会形成一个一致性哈希环,沿着这个环往下找,直至找到。
当然这里key.hashcode*()% 2^32-1只是举个例子,实际生产中我们会采用哈希算法,如MD5、MurMurHash、crc32将数据映射到一个哈希环上。

3. 假如在新增一台redis服务器C前,数据存在节点A。加入C后,客户端在操作的时候,会出现什么问题?
查找数据时,如果通过一致性哈希算法得出数据在C上,但真实数据在A上,客户端在C上查找会找不到数据就会报空指针异常。
这个其实是在redis2.X中的问题,因为redis2.X不支持冬天扩容。这时我们可以考虑找一个合适的时间点如业务峰值低的时候,将环中的所有数据加载出来,灌入到另外一个新增节点后的环中进行处理。
4. redis3.X如何解决redis2.X的上述问题?
通过上面的问题可以得知redis2.X不支持动态加节点,就算成功加入新节点,数据会发生错乱现象,而redis3.X解决了这个问题:
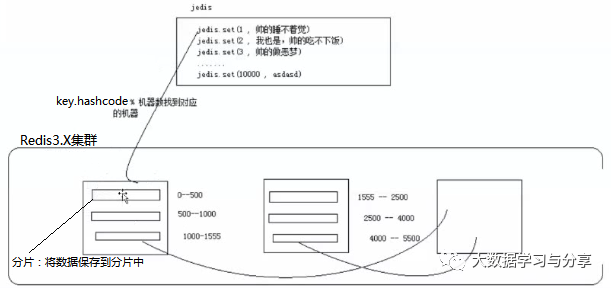
redis集群内置了16384个哈希槽,当需要在集群中插入数据时,先对key使用crc16算法得出一个结果,然后把结果对16384求余数。这样每个key都会对应一个编号在0~16383之间的哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同节点。
redis集群的每个节点负责一部分哈希槽,这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。哈希槽的好处在于可以方便的添加或移除节点:
1)当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了
2)当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了
5. redis3.X的hash碰撞问题
通过hash映射,当某台机器上数据过多支撑不住导致宕机,此时它负责的数据会分配到其他机器,而redis集群服务器配置一般相同,其他机器也扛不住,就会造成雪崩,即便有主备也解决不了,最终可能导致整个集群都会挂掉。下图演示了节点C宕机,C上的数据映射到D上的示例:
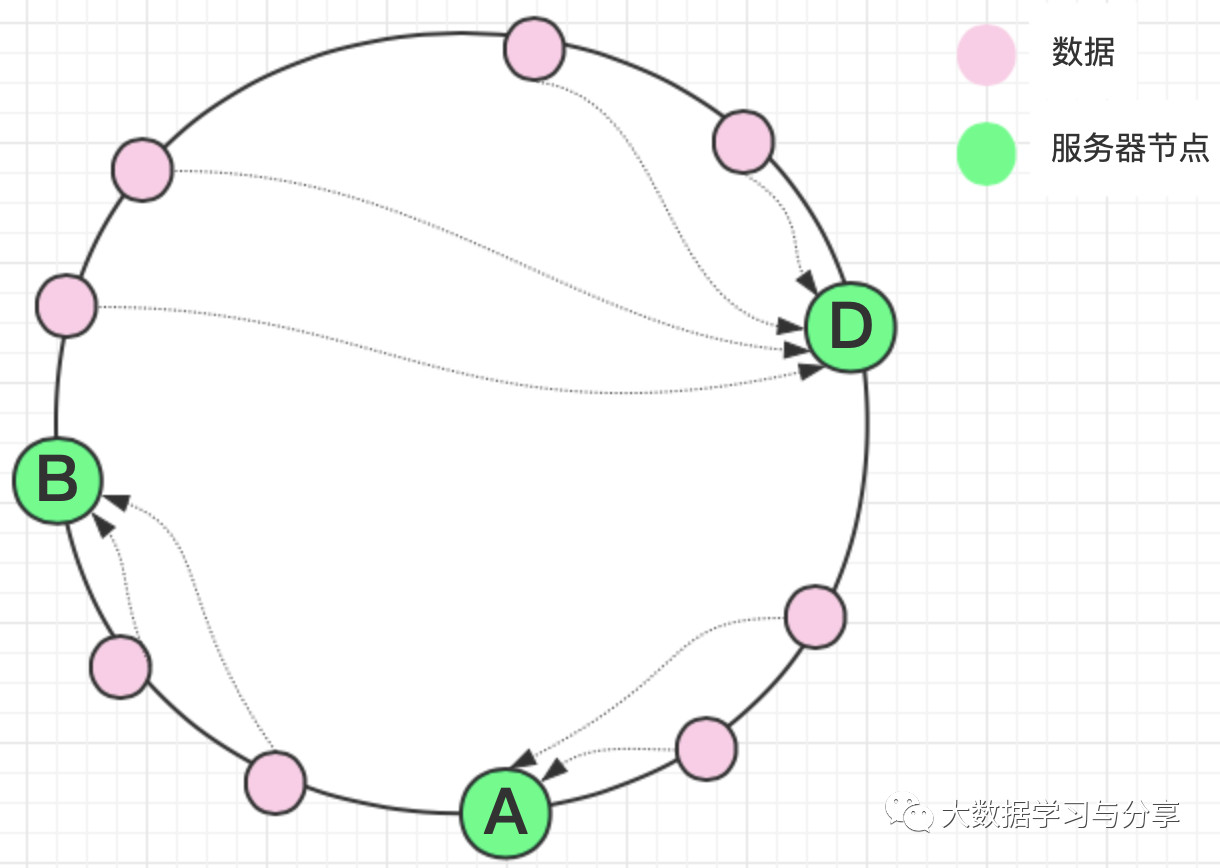
这其实就是分布式系统中极其常见的问题,数据倾斜。可以考虑通过如下方式解决:
1)如给大量相似数据即key相同,给key加上随机串,将key打散尽可能随机分配,避免数据倾斜
2)参考redis2.X版本中"虚拟节点"的做法,为每个真实节点引入N个虚拟节点。具体看下文
6. redis2.X是如何解决hash碰撞的问题?redis2.X有一个非常重要的概念:虚拟节点,每个节点都虚拟出160个虚拟节点。数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点。
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载A1、A2的数据,机器B负载B1、B2的数据,机器C负载C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成"雪崩"现象。
相关推荐



0评论