这篇文章主要介绍了Tensorflow 实现线性回归模型,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
1.线性与非线性回归
线性回归 Linear Regression:两个变量之间的关系是一次函数关系的——图像是直线,叫做线性。线性是指广义的线性,也就是数据与数据之间的关系,如图x1。
非线性回归:两个变量之间的关系不是一次函数关系的——图像不是直线,叫做非线性,如图x2。
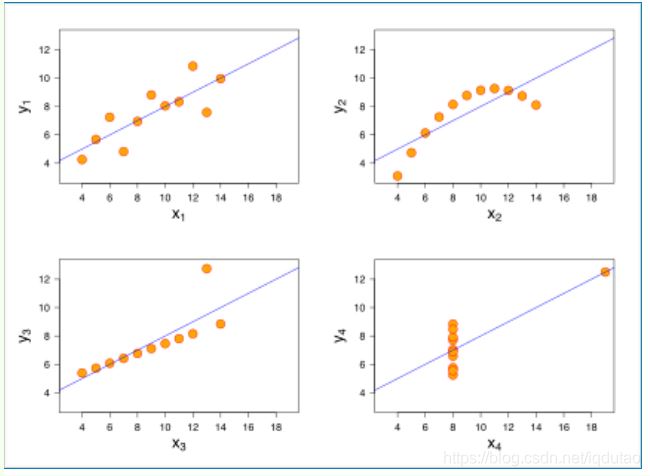
一元线性回归:只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。函数表达: y=bx+a。
多元线性回归:包括两个或两个以上相互独立的自变量(x1,x2,x3...),且因变量(y)和自变量之间是线性关系,则称为多元线性回归分析。函数表达:

线性回归在深度学习中的应用: 在深度学习中,我们就是要根据已知数据点(自变量)和因变量(y)去训练模型得到未知参数a和b、 和的具体值,从而得到预测模型,在这里()相当于深度学习中目标对象的特征,(y)相当于具体的目标对象。得到预测模型之后再对未知的自变量x进行预测,得到预测的y。
线性回归问题与分类问题:与回归相对的是分类问题(classification),分类问题预测输出的y值是有限的,预测值y只能是有限集合内的一个。而当要预测值y输出集合是无限且连续,我们称之为回归。比如,天气预报预测明天是否下雨,是一个二分类问题;预测明天的降雨量多少,就是一个回归问题。
案例讲解
了解基础概念之后,使用Tensorflow实现一个简单的一元线性回归问题, 调查学历和收入之间的线性关系,如下所示:

求解未知参数a和b的方法:
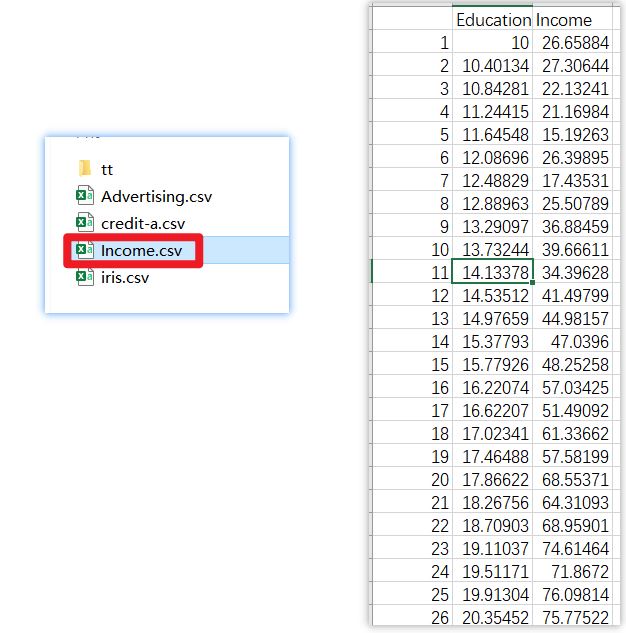
1.数据集
模型训练的数据存储在一个.csv文件里,Education代表学历【自变量x】,Income代表收入【因变量y】。
目标:我们要利用已知的Education和income数据值,求解未知参数a和b的值,得到Education和Income之间的线性关系。
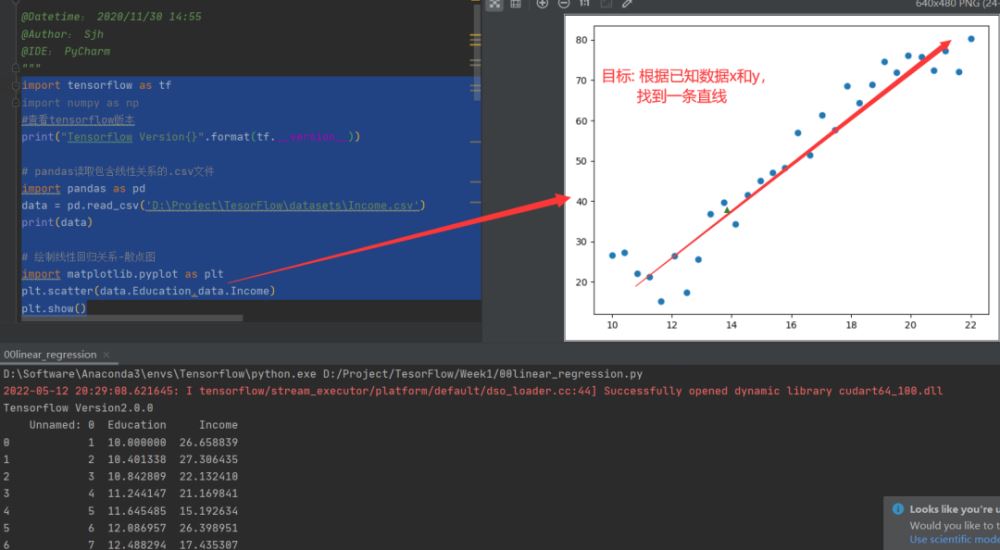
2.读取训练数据Income.csv并可视化展示
import tensorflow as tf
import numpy as np
# 1.查看tensorflow版本
print("Tensorflow Version{}".format(tf.__version__))
# 2.pandas读取包含线性关系的.csv文件
import pandas as pd
data = pd.read_csv('D:\Project\TesorFlow\datasets\Income.csv')
print(data)
# 3.绘制线性回归关系-散点图
import matplotlib.pyplot as plt
plt.scatter(data.Education,data.Income)
plt.show()
3.利用Tensorflow搭建和训练神经网络模型【线性回归模型的建立】
# 4.顺序模型squential的建立 # 顺序模型是指网络是一层一层搭建的,前面一层的输出是后一层的输入。 model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(1,input_shape=(1,))) # dense(输出数据的维度,输入数据的维度) # 5.查看模型的结构 model.summary() # 6.编译模型 - 配置的过程, 优化算法方式(梯度下降)、损失函数 # Adam优化器的学习速率默认为0.01 model.compile(optimizer='adam', loss = 'mse') # 7.训练模型,记录模型的训练过程 history # 训练过程是loss函数值降低的过程: # 即不断逼近最优的a和b参数值的过程 # 这个过程要训练很多次epoch,epoch是指对所有训练数据训练的次数 history = model.fit(x,y,epochs=100)
model.summary(): 查看我们创建的神经网络模型,这里我们只添加了一层全连接层。
训练过程:这里只训练100个epoch.
4. 模型预测
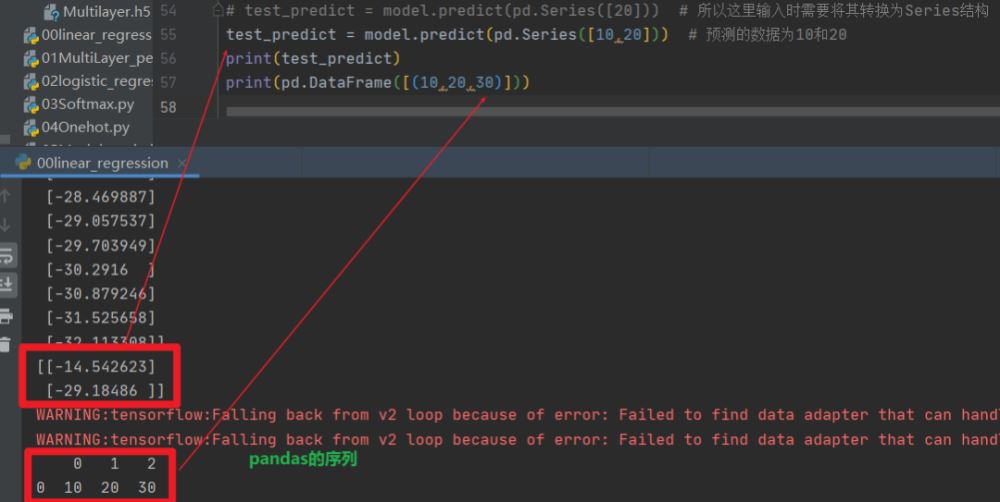
# 8.已知数据预测 model.predict(x) print(model.predict(x)) # 9.随机数据预测: # """ # 注意:pandas数据结构是数据框DataFrame和 序列 Series # 序列(Series)是二维表格中的一列或者一行。实际上,当访问DataFrame的一行时,pandas自动把该行转换为序列;当访问DataFrame的一列时,Pandas也自动把该列转换为序列。 # 序列是由一组数据(各种NumPy数据类型),以及一组与之相关的数据标签(索引)组成,序列不要求数据类型是相同的,序列可以看作是一维数组(一行或一列) # 序列的表现形式为:索引在左边,值在右边。由于没有显式为Series指定索引,pandas会自动创建一个从0到N-1的整数型索引。 # """ # test_predict = model.predict(pd.Series([20])) # 所以这里输入时需要将其转换为Series结构 test_predict = model.predict(pd.Series([10,20])) # 预测的数据为10和20 print(test_predict) print(pd.DataFrame([(10,20,30)]))
已知结果的数据预测的结果: 查看我们创建的神经网络模型,这里我们只添加了一层全连接层。

未知结果的数据预测的结果: 可以看到预测结果很差,说明我们的神经网络模型并没有训练好,求解得到的未知参数的a和b的值很差。
解决办法:: 加深神经网络模型的参数,训练更多的次数epoch或者添加实验数据。
sklearn库有写好了的线性回归函数,from sklearn.linear_model import LinearRegression直接导入即可。
相关推荐



0评论