SQL去重是数据分析工作中比较常见的一个场景,下面这篇文章主要给大家介绍了关于SQL数据去重的3种方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下
1、使用distinct去重
distinct用来查询不重复记录的条数,用count(distinct id)来返回不重复字段的条数。用法注意:
distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
DISTINCT 表示对后面的所有参数的拼接取不重复的记录,即查出的参数拼接每行记录都是唯一的
不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
distinct支持单列、多列的去重方式。
作用于单列
单列去重的方式简明易懂,即相同值只保留1个。
select distinct name from A //对A表的name去重然后显示
作用于多列
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。注意,distinct作用于多列的时候只在开头加上即可,并不用每个字段都加上。distinct必须在开头,在中间是不可以的,会报错,`select id,distinct name from A //错误
select distinct id,name from A //对A表的id和name去重然后显示
配合count使用
select count(distinct name) from A //对A表的不同的name进行计数
按顺序去重时,order by 的列必须出现在 distinct 中
出错代码
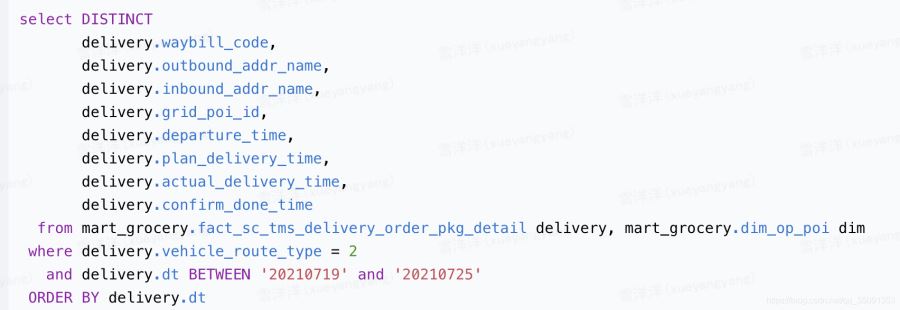
改正后的代码
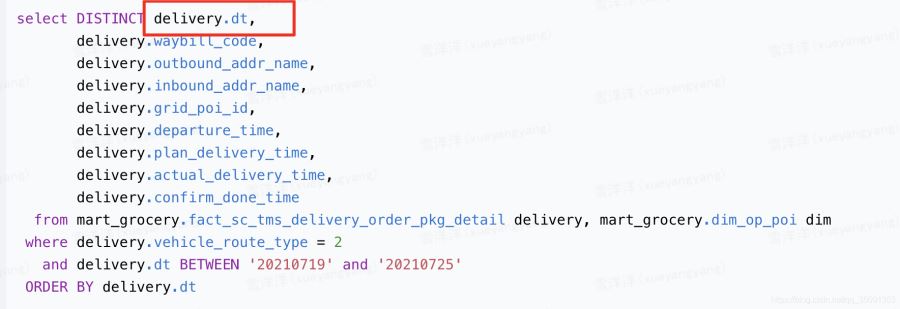
讨论:若不使用Distinct关键字,则order by后面的字段不一定要放在seletc中
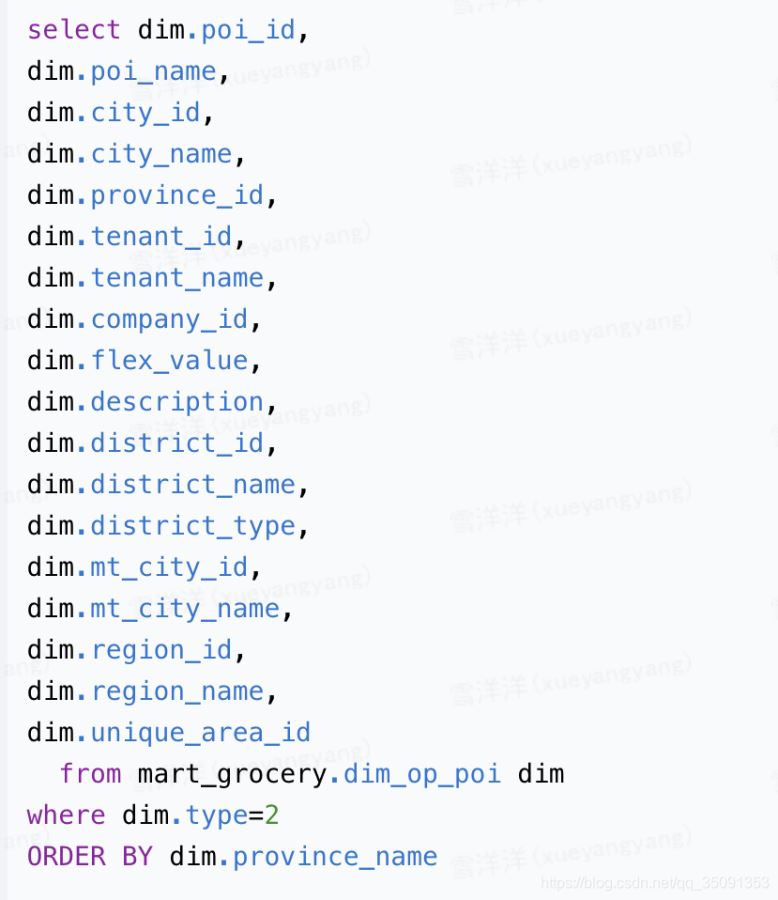
MySQL中使用去重distinct方法的示例详解
【Hive】数据去重
2、使用group by
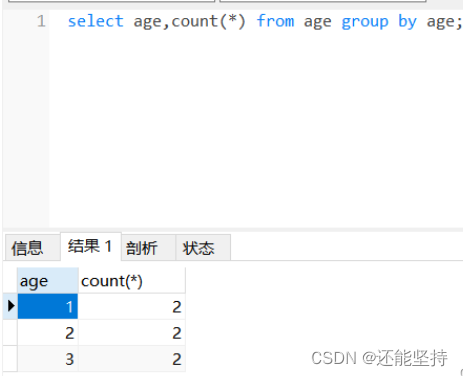
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数,形式为select 重复的字段名 from 表名 group by 重复的字段名;
group by 对age查询结果进行了分组,自动将重复的项归结为一组。
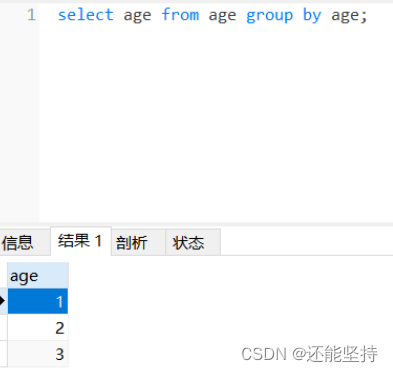
还可以使用count函数,统计重复的数据有多少个
3、使用ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST
说到要去重,自然会想到 DISTINCT,但是在 Hive SQL 里,它有两个问题:
DISTINCT 会以 SELECT 出的全部列作为 key 进行去重。也就是说,只要有一列的数据不同,DISTINCT 就认为是不同数据而保留。
DISTINCT 会将全部数据打到一个 reducer 上执行,造成严重的数据倾斜,耗时巨大。
3.1 ROW_NUMBER() OVER
DISTINCT 的两个问题,用 ROW_NUMBER() OVER 可解。比如,如果我们要按 key1 和 key2 两列为 key 去重,就会写出这样的代码:
WITH temp_table AS ( SELECT key1, key2, [columns]..., ROW_NUMBER() OVER ( PARTITION BY key1, key2 ORDER BY column ASC ) AS rn FROM table ) SELECT key1, key2, [columns]... FROM temp_table WHERE rn = 1;
这样,Hive 会按 key1 和 key2 为 key,将数据打到不同的 mapper 上,然后对 key1 和 key2 都相同的一组数据,按 column 升序排列,并最终在每组中保留排列后的第一条数据。借此就完成了按 key1 和 key2 两列为 key 的去重任务。注意 PARTITION BY 在此起到的作用:
一是按 key1 和 key2 打散数据,解决上述问题 (2);
二是与 ORDER BY 和 rn = 1 的条件结合,按 key1 和 key2 对数据进行分组去重,解决上述问题 (1)。
但显然,这样做十分不优雅(not-elegant),并且不难想见其效率比较低。
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) as num 表示根据 COL1分组,在分组内部根据 COL2排序,此函数计算的值num就表示每组内部排序后的顺序编号(组内连续的唯一的)
3.2 GROUP BY 和 COLLECT_SET/COLLECT_LIST
ROW_NUMBER() OVER 解法的一个核心是利用 PARTITION BY 对数据按 key 分组,同样的功能用 GROUP BY 也可以实现。但是,GROUP BY 需要与聚合函数搭配使用。我们需要考虑,什么样的聚合函数能实现或者间接实现这样的功能呢?不难想到有 COLLECT_SET 和 COLLECT_LIST。
SELECT key1, key2, [COLLECT_LIST(column)[1] AS column]... FROM temp_table GROUP BY key1, key2
对于 key1 和 key2 以外的列,我们用 COLLECT_LIST 将他们收集起来,然后输出第一个收集进来的结果。这里使用 COLLECT_LIST 而非 COLLECT_SET 的原因在于 SET 内是无序的,因此你无法保证输出的 columns 都来自同一条数据。若对于此没有要求或限制,则可以使用 COLLECT_SET,它会更节省资源。
相比前一种办法,由于省略了排序和(可能的)落盘动作,所以效率会高不少。但是因为(可能)不落盘,所以 COLLECT_LIST 中的数据都会缓存在内存当中。如果重复数量特别大,这种方法可能会触发 OOM。此时应考虑将数据进一步打散,然后再合并;或者干脆换用前一种办法。
distinct与group by的去重方面的区别
distinct简单来说就是用来去重的,而group by的设计目的则是用来聚合统计的,两者在能够实现的功能上有些相同之处,但应该仔细区分。
单纯的去重操作使用distinct,速度是快于group by的。
distinct支持单列、多列的去重方式。
单列去重的方式简明易懂,即相同值只保留1个。
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
group by使用的频率相对较高,但正如其功能一样,它的目的是用来进行聚合统计的,虽然也可能实现去重的功能,但这并不是它的长项。
区别:
1)distinct只是将重复的行从结果中出去;
group by是按指定的列分组,一般这时在select中会用到聚合函数。
2)distinct是把不同的记录显示出来。
group by是在查询时先把纪录按照类别分出来再查询。
group by 必须在查询结果中包含一个聚集函数,而distinct不用。
distinct和group by有啥区别,大概总结以下几点:
distinct适合查单个字段去重,支持单列、多列的去重方式。 单列去重的方式简明易懂,即相同值只保留1个。
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。
补充:MySQL中distinct和group by去重性能对比
前言
MySQL:5.7.17
存储引擎:InnoDB
实验目的:本文主要测试在某字段有无索引、各种不同值个数情况下,记录对此字段其使用DISTINCT/GROUP BY去重的查询语句执行时间,对比两者在不同场景下的去重性能,实验过程中关闭MySQL查询缓存。
实验表格:
| 表名 | 记录数 | 查询字段有无索引 | 查询字段不同值个数 | DISTINCT | GROUP BY |
|---|---|---|---|---|---|
| tab_1 | 100000 | N | 3 | ||
| tab_2 | 100000 | Y | 3 | ||
| tab_3 | 100000 | N | 10000 | ||
| tab_4 | 100000 | Y | 10000 |
实验过程
1)创建测试表
表创建语句:
DROP TABLE IF EXISTS `tab_1`; CREATE TABLE `tab_1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `value` int(10) unsigned NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `tab_2`; CREATE TABLE `tab_2` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `value` int(10) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `idx_value` (`value`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `tab_3`; CREATE TABLE `tab_3` LIKE `tab_1`; DROP TABLE IF EXISTS `tab_4`; CREATE TABLE `tab_4` LIKE `tab_2`;
2)生成测试数据
表数据插入过程:
DROP PROCEDURE IF EXISTS generateRandomData;
delimiter $$
-- tblName为插入表,field为插入字段,num为插入字段值上限,count为插入的记录数
CREATE PROCEDURE generateRandomData(IN tblName VARCHAR(30),IN field VARCHAR(30),
IN num INT UNSIGNED,IN count INT UNSIGNED)
BEGIN
-- 声明循环变量
DECLARE i INT UNSIGNED DEFAULT 1;
-- 循环插入随机整数1~num,共插入count条数据
w1:WHILE i<=count DO
set i=i+1;
set @val = FLOOR(RAND()*num+1);
set @statement = CONCAT('INSERT INTO ',tblName,'(`',field,'`) VALUES(',@val,')');
PREPARE stmt FROM @statement;
EXECUTE stmt;
END WHILE w1;
END $$
delimiter ;调用过程随机生成测试数据:
call generateRandomData('tab_1','value',3,100000);
INSERT INTO tab_2 SELECT * FROM tab_1;
call generateRandomData('tab_3','value',10000,100000);
INSERT INTO tab_4 SELECT * FROM tab_3;3)执行查询语句,记录执行时间
查询语句及对应执行时间如下:
SELECT DISTINCT(`value`) FROM tab_1; SELECT `value` FROM tab_1 GROUP BY `value`; SELECT DISTINCT(`value`) FROM tab_2; SELECT `value` FROM tab_2 GROUP BY `value`; SELECT DISTINCT(`value`) FROM tab_3; SELECT `value` FROM tab_3 GROUP BY `value`; SELECT DISTINCT(`value`) FROM tab_4; SELECT `value` FROM tab_4 GROUP BY `value`;
4)实验结果
| 表名 | 记录数 | 查询字段有无索引 | 查询字段不同值个数 | DISTINCT | GROUP BY |
|---|---|---|---|---|---|
| tab_1 | 100000 | N | 3 | 0.058s | 0.059s |
| tab_2 | 100000 | Y | 3 | 0.030s | 0.027s |
| tab_3 | 100000 | N | 10000 | 0.072s | 0.073s |
| tab_4 | 100000 | Y | 10000 | 0.047s | 0.049s |
实验结论
MySQL 5.7.17中使用distinct和group by进行去重时,性能相差不大
使用去重distinct方法的示例详解
一 distinct
含义:distinct用来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段
用法注意:
1.distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
2.只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
3.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,即查出的参数拼接每行记录都是唯一的
4.不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
1.1只对一个字段查重
对一个字段查重,表示选取该字段一列不重复的数据。
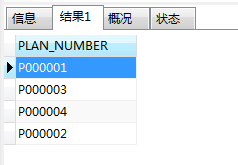
示例表:psur_list

PLAN_NUMBER字段去重,语句:
SELECT DISTINCT PLAN_NUMBER FROM psur_list;
结果如下:
1.2多个字段去重
对多个字段去重,表示选取多个字段拼接的一条记录,不重复的所有记录
示例表:psur_list
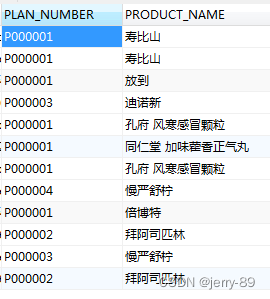
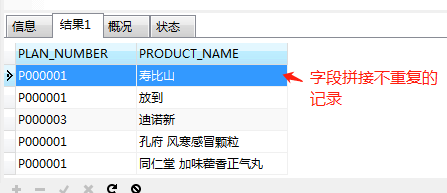
PLAN_NUMBER和PRODUCT_NAME字段去重,语句:
SELECT DISTINCT PLAN_NUMBER,PRODUCT_NAME FROM psur_list;
结果如下:
期望结果:只对第一个参数PLAN_NUMBER取唯一值
解决办法一:使用group_concat 函数
语句:
SELECT GROUP_CONCAT(DISTINCT PLAN_NUMBER) AS PLAN_NUMBER,PRODUCT_NAMEFROM psur_list GROUP BY PLAN_NUMBER
解决办法二:使用group by
语句:
SELECT PLAN_NUMBER,PRODUCT_NAME FROM psur_list GROUP BY PLAN_NUMBER
结果如下:

1.3针对null处理
distinct不会过滤掉null值,返回结果包含null值
表psur_list如下:
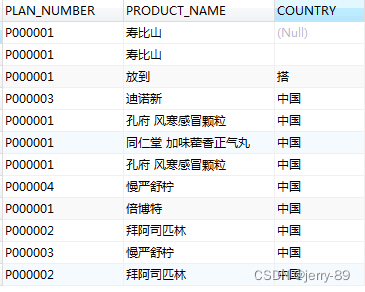
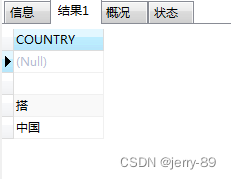
对COUNTRY字段去重,语句:
SELECT DISTINCT COUNTRY FROM psur_list
结果如下:
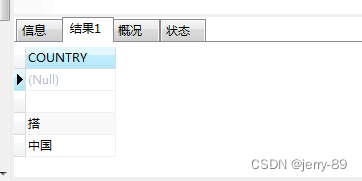
1.4与distinctrow同义
语句:
SELECT DISTINCTROW COUNTRY FROM psur_list
结果如下:
二 聚合函数中使用distinct
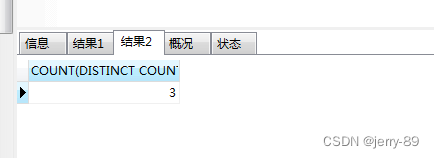
在聚合函数中DISTINCT 一般跟 COUNT 结合使用。count()会过滤掉null项
语句:
SELECT COUNT(DISTINCT COUNTRY) FROM psur_list
结果如下:【实际包含null项有4个记录,执行语句后过滤null项,计算为3】
相关推荐



0评论