在做时间序列分析时,我们经常要对时间序列进行平稳性检验,而我们常用的软件是SPSS或SAS,但实际上python也可以用来做平稳性检验,而且效果也非常好,今天笔者就讲解一下如何用python来做时间序列的平稳性检验。
首先我们还是来简单介绍一下平稳性检验的相关概念。

图1. 平稳性序列的相关公式
时间序列的平稳性可分为严平稳和宽平稳。设{Xt}是一时间序列,对任意正整数m,任取t1、t2、t3、...、tm∈T,对任意整数τ,假如满足图1中式(1),则称时间序列{Xt}是严平稳时间序列。而宽平稳的定义为,如果{Xt}满足以下三个条件:
(1)任取t∈T,有E(Xt·Xt)<∞;
(2)任取t∈T,有E Xt =μ,μ为常数;
(3)任取t,s,k∈T,且k+s-t∈T,有γ(t, s)=γ(k, k+s-t)
则称{Xt}为宽平稳时间序列。
因为实际应用中我们很难获得随机序列的分布函数,所以严平稳用得极少,主要是使用宽平稳时间序列。
在了解了平稳性的基本概念之后,我们再来说一下平稳时间序列的意义。平稳时间序列的分析也遵循数理统计学的基本原理,都是利用样本信息来推测总体信息。这就要求分析的随机变量越少越好(也就是数据的维度越小越好),而每个变量获得样本信息越多越好(也就是数据的观测值越大越好),因为随机变量越少,分析过程越简单,样本容量越大,分析的结果越可靠。但时间序列的数据结构有其特殊性,它在任意时刻t的序列值Xt都是一个随机变量,而且由于时间的不可重复性,该变量在任意一个时刻只能获得唯一的样本观测值。由于样本信息太少,如果没有其他的辅助信息,这种数据结构通常是没有办法分析的,但序列平稳性就可以有效解决这个问题。在平稳序列中,序列的均值等于常数就意味着原本含有可列多个随机变量的均值序列{μt, t∈T}变成了一个常数序列{μ, t∈T},原本每个随机变量的均值μt只能依靠唯一的一个样本观察值xt去估计,现在由于μt=μ,于是每一个样本观察值xt,都变成了常数均值的样本观察值,如图1中式(2)所示。这就极大减少了随机变量的个数,并增加了待估参数的样本容量,这也就降低了时序分析的难度。
在了解了时间序列的平稳性之后,我们再来详细讲解一下如何用python来进行检验。
用python来进行平稳性检验主要有3种方法,分别是时序图检验、自相关图检验以及构造统计量进行检验。
首先来说时序图检验,时序图就是普通的时间序列图,即以时间为横轴,观察值为纵轴进行检验。这里笔者给出3个例子,因为时序图过于简单,所以笔者在这里直接用Excel作时序图,用python也可以,不过没有Excel简单。第一个例子是1964-1999年中国纱年产量时间序列(该数据来自北京统计局),其数据如图2所示,序列图如图3所示。图3中明显可以看出,中国纱年产量序列有明显的递增趋势,所以它一定不是平稳序列。
图2. 纱产量部分数据截图
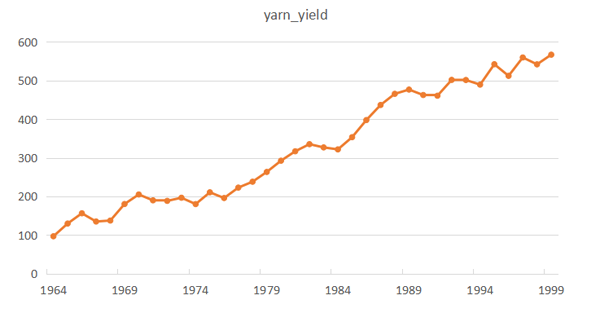
图3. 纱产量时序图
第二个例子是1962年1月至1975年12月平均每头奶牛月产奶量时间序列(数据来自网站http://census-info.us),其数据如图4所示,序列图如图5所示。从图5中可以看出,平均每头奶牛的月产奶量以年为周期呈规则的周期性,此外还有明显的逐年递增趋势,所以该序列也一定不是平稳序列。
图4. 奶牛产量部分数据截图
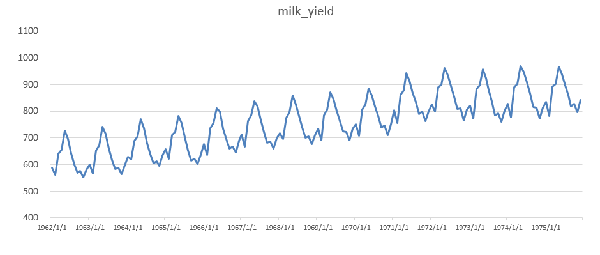
图5. 奶牛产量时序图
第三个例子是1949年至1998年北京市每年最高气温序列(数据来自北京市统计局),其数据如图6所示,序列图如图7所示。从图7中可以看出,北京市每年的最高气温始终围绕在37度附近随机波动,没有明显趋势或周期,基本可以视为平稳序列,但我们还需要利用自相关图进一步验证。

图6. 北京最高气温部分数据截图
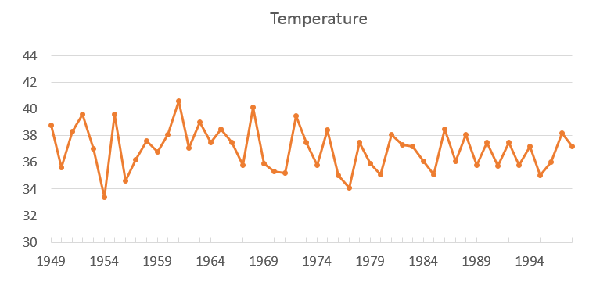
图7. 北京最高气温时序图
从上面的例子可以看出,时序图只能粗略来判断一个时间序列是否为平稳序列,我们可以用自相关图来更进一步检验。要画自相关图,我们就要用到python,下面是相关代码。
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
temperature = r'C:\Users\北京气温.xls'
milk = r'C:\Users\奶牛产量.xlsx'
yarn = r'C:\Users\纱产量.xls'
data_tem = pd.read_excel(temperature, parse_date=True)
data_milk = pd.read_excel(milk, parse_date=True)
data_yarn = pd.read_excel(yarn, parse_date=True)
plt.rcParams.update({'figure.figsize':(8,6), 'figure.dpi':100}) #设置图片大小
plot_acf(data_tem.Tem) #生成自相关图
plot_acf(data_milk.milk_yield)
plot_acf(data_yarn.yarn_yield)
plt.show()画自相关图用到的是statsmodels中的plot_acf方法,这个方法很简单,只需要直接输入数据即可,不过数据要是一维的,生成的3张图如图8、图9和图10所示。
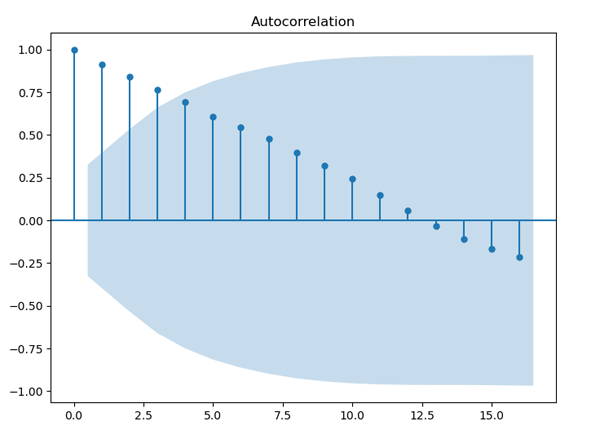
图8. 纱产量自相关图
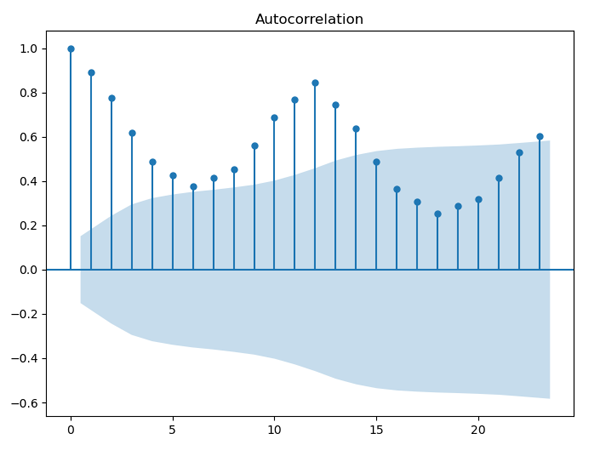
图9. 奶牛产量自相关图
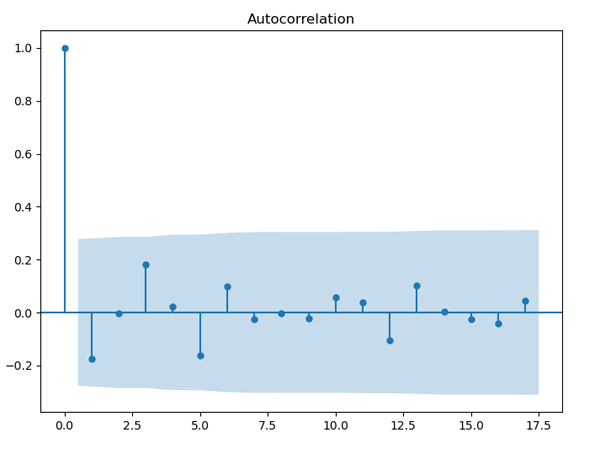
图10. 北京最高气温自相关图
平稳序列通常具有短期相关性,即随着延迟期数k的增加,平稳序列的自相关系数会很快地衰减向零,而非平稳序列的自相关系数的衰减速度会比较慢,这就是我们利用自相关图判断平稳性的标准。我们就来看下这3张自相关图,图8是纱年产量的自相关图,其横轴表示延迟期数,纵轴表示自相关系数,从图中可以看出自相关系数衰减到零的速度比较缓慢,在很长的延迟期内,自相关系数一直为正,然后为负,呈现出三角对称性,这是具有单调趋势的非平稳序列的一种典型的自相关图形式。再来看看图9,这是每头奶牛的月产奶量的自相关图,图中自相关系数长期位于零轴一边,这是具有单调趋势序列的典型特征,同时还呈现出明显的正弦波动规律,这是具有周期变化规律的非平稳序列的典型特征。最后再来看下图10,这是北京每年最高气温的自相关图,图中显示该序列的自相关系数一直比较小,可以认为该序列一直在零轴附近波动,这是随机性较强的平稳序列通常具有的自相关图。
最后我们再讲一下ADF方法。前面两种方法都是作图,图的特点是比较直观,但不够精确,而ADF法则是直接通过假设检验的方式来验证平稳性。ADF(全称Augmented Dickey-Fuller)是一种单位根检验方法,单位根检验方法比较多,而ADF法是比较常用的一种,其和普通的假设检验没有太大区别,都是列出原假设和备择假设。ADF的原假设(H0)和备择假设(H1)如下。
H0:具有单位根,属于非平稳序列。
H1:没有单位根,属于平稳序列,说明这个序列不具有时间依赖型结构。
下面我们就用python代码来解释一下ADF的用法。
from statsmodels.tsa.stattools import adfuller
yarn_result = adfuller(data_yarn.yarn_yield) #生成adf检验结果
milk_result = adfuller(data_milk.milk_yield)
tem_result = adfuller(data_tem.Tem)
print('The ADF Statistic of yarn yield: %f' % yarn_result[0])
print('The p value of yarn yield: %f' % yarn_result[1])
print('The ADF Statistic of milk yield: %f' % milk_result[0])
print('The p value of milk yield: %f' % milk_result[1])
print('The ADF Statistic of Beijing temperature: %f' % tem_result[0])
print('The p value of Beijing temperature: %f' % tem_result[1])这里我们用的是statsmodels中的adfuller方法,其使用也比较简单,直接输入数据即可,但其返回值较多,返回的结果中共有7个值,分别是adf、pvalue、usedlag、nobs、critical values、icbest和resstore,这7个值的意义大家可以参考官方文档,我们这里用到的是前两个,即adf和pvalue,adf就是ADF方法的检验结果,而pvalue就是我们常用的p值。我们的得到结果如图11所示。

图11. ADF检验结果
在图11中,我们可以看到,纱产量、奶牛产量和北京气温的adf值分别是-0.016384、-1.303812和-8.294675,这个值理论上越负越能拒绝原假设,但我们在这里不用adf来判断,而是用p值。这3个p值分别是0.957156、0.627427和0.000000,以常用的判断标准值0.05作为参考,前两个p值都远大于0.05,说明其是支持原假设的,说明纱产量和奶牛产量都是非平稳序列,而北京气温序列的p值为零,说明是拒绝原假设,表明该序列是一个平稳序列。我们可以看到,利用adf法和前面两种方法得到的结果是一致的。
本文比较详细地介绍了判断时间序列平稳性的3种方法,这3种方法在实际应用中是经常用到的,当然判断平稳性的方法还有很多种,大家如有需要也可以自行查找相关资料。
相关推荐



0评论